コメント一覧
まえへ つぎへ96 投稿者:名無しさん 2020/01/20 16:33:28

97 投稿者:名無しさん 2020/01/20 16:33:32
98 投稿者:名無しさん 2020/01/21 12:19:27
#include <stdio.h>
#include <math.h>
#define M 10
#define N 100
// c*c 熱伝導係数=1
// r = k / h / h = c * c * k / h / h
//
// ( r <= 1 / 2 )
// r -> 1 のときうまくいかない
// h=0.2 -> k でrの条件を満たすべき
//iがx方向
//jが時間t
//jが0なおかつI->...
int main(void) {
int i, j, m, n;
float u[M + 1][N + 1], r, k, h, er, x, t;
printf("interval of position(h)= : ");
scanf("%f", &h);
printf("interval of time(k)= : ");
scanf("%f", &k);
r = k / h / h;
printf("r=%f\n", r);
m = (int)(1.0 / h + 0.5);
n = (int)(1.0 / k + 0.5);
printf("m=%d n=%d\n", m, n);
for (j = 0; j <= n; j++) {
for (i = 0; i <= m; i++) {
x = i * h;
if ((x == 0 || x == 1) && j >= 0)
u[i][j] = 0.0;
else if (x >= 0 && x <= 0.5 && j == 0)
u[i][j] = 2.0 * x;
else if (x >= 0.5 && x <= 1 && j == 0)
u[i][j] = 2.0 * (1.0 - x);
else
u[i][j] = 0.0;
}
}
for (j = 0; j < n; j++) {
for (i = 1; i < m; i++) {
u[i][j + 1] = (1.0 - 2.0 * r) * u[i][j]
+ r * (u[i + 1][j] + u[i - 1][j]);
}
}
for (j = 0; j <= n; j++) {
printf("%7.3f", k * j);
for (i = 0; i <= m; i++)
printf("%7.3f", u[i][j]);
printf("\n");
}
}
/*
shion@PC-9821Air ~ % sh comp.sh m
interval of position(h)= : 0.2
interval of time(k)= : 0.02
r=0.500000
m=5 n=50
0.000 0.000 0.400 0.800 0.800 0.400 0.000
0.020 0.000 0.400 0.600 0.600 0.400 0.000
0.040 0.000 0.300 0.500 0.500 0.300 0.000
0.060 0.000 0.250 0.400 0.400 0.250 0.000
0.080 0.000 0.200 0.325 0.325 0.200 0.000
0.100 0.000 0.162 0.262 0.262 0.162 0.000
0.120 0.000 0.131 0.212 0.212 0.131 0.000
0.140 0.000 0.106 0.172 0.172 0.106 0.000
0.160 0.000 0.086 0.139 0.139 0.086 0.000
0.180 0.000 0.070 0.112 0.112 0.070 0.000
0.200 0.000 0.056 0.091 0.091 0.056 0.000
0.220 0.000 0.046 0.074 0.074 0.046 0.000
0.240 0.000 0.037 0.060 0.060 0.037 0.000
0.260 0.000 0.030 0.048 0.048 0.030 0.000
0.280 0.000 0.024 0.039 0.039 0.024 0.000
0.300 0.000 0.019 0.032 0.032 0.019 0.000
0.320 0.000 0.016 0.026 0.026 0.016 0.000
0.340 0.000 0.013 0.021 0.021 0.013 0.000
0.360 0.000 0.010 0.017 0.017 0.010 0.000
0.380 0.000 0.008 0.014 0.014 0.008 0.000
0.400 0.000 0.007 0.011 0.011 0.007 0.000
0.420 0.000 0.005 0.009 0.009 0.005 0.000
0.440 0.000 0.004 0.007 0.007 0.004 0.000
0.460 0.000 0.004 0.006 0.006 0.004 0.000
0.480 0.000 0.003 0.005 0.005 0.003 0.000
0.500 0.000 0.002 0.004 0.004 0.002 0.000
0.520 0.000 0.002 0.003 0.003 0.002 0.000
0.540 0.000 0.002 0.002 0.002 0.002 0.000
0.560 0.000 0.001 0.002 0.002 0.001 0.000
0.580 0.000 0.001 0.002 0.002 0.001 0.000
0.600 0.000 0.001 0.001 0.001 0.001 0.000
0.620 0.000 0.001 0.001 0.001 0.001 0.000
0.640 0.000 0.001 0.001 0.001 0.001 0.000
0.660 0.000 0.000 0.001 0.001 0.000 0.000
0.680 0.000 0.000 0.001 0.001 0.000 0.000
0.700 0.000 0.000 0.000 0.000 0.000 0.000
0.720 0.000 0.000 0.000 0.000 0.000 0.000
0.740 0.000 0.000 0.000 0.000 0.000 0.000
0.760 0.000 0.000 0.000 0.000 0.000 0.000
0.780 0.000 0.000 0.000 0.000 0.000 0.000
0.800 0.000 0.000 0.000 0.000 0.000 0.000
0.820 0.000 0.000 0.000 0.000 0.000 0.000
0.840 0.000 0.000 0.000 0.000 0.000 0.000
0.860 0.000 0.000 0.000 0.000 0.000 0.000
0.880 0.000 0.000 0.000 0.000 0.000 0.000
0.900 0.000 0.000 0.000 0.000 0.000 0.000
0.920 0.000 0.000 0.000 0.000 0.000 0.000
0.940 0.000 0.000 0.000 0.000 0.000 0.000
0.960 0.000 0.000 0.000 0.000 0.000 0.000
0.980 0.000 0.000 0.000 0.000 0.000 0.000
1.000 0.000 0.000 0.000 0.000 0.000 0.000
*/
99 投稿者:名無しさん 2020/01/22 10:21:37
100 投稿者:名無しさん 2020/01/22 10:21:48
import os, sys, math
from sklearn import datasets, svm
from sklearn.externals import joblib
DIGITS_PKL = "digit-clf.pkl"
def train_digits():
digits = datasets.load_digits()
data_train = digits.data
label_train =digitas.target
clf = svm.SVC(gamma=0.001)
clf.fit(data_train, lael_train)
joblib.dump(clf,DIGITS_PKL)
print("予測モデルを保存しました=",DIGITS_PKL)
return clf
def predict_digits(data):
if not os.path.exists(DIGITS_PKL):
clf = train_digits()
clf = joblib.load(DIGITS_PKL)
n = clf.predict([data])
prnt("判定結果=",n)
def image_to_data(imagefile):
import numpy as np
from PIL import Image
image = Image.open(imagefile).convert("L")
image = image.resize((8,8),Image.ANTIALIAS)
img = np.asarray(image, dtype = float)
img = np.fllor(16-16*(img/256))
import matplotlib.pyplot as plt
plt.imshow(img)
plt.gray()
plt.show()
img = img.flatten()
print(img)
return img
def main():
if len(sys.argv) <=1:
print("USAGE:")
print("python3 predict_digit.py imagefile")
return
imagefile = sys.argv[1]
data = image_to_data(imagefile)
predict_digits(data)
if __name__=='__main__':
main()
101 投稿者:名無しさん 2020/01/22 11:51:23

102 投稿者:名無しさん 2020/01/22 13:05:22
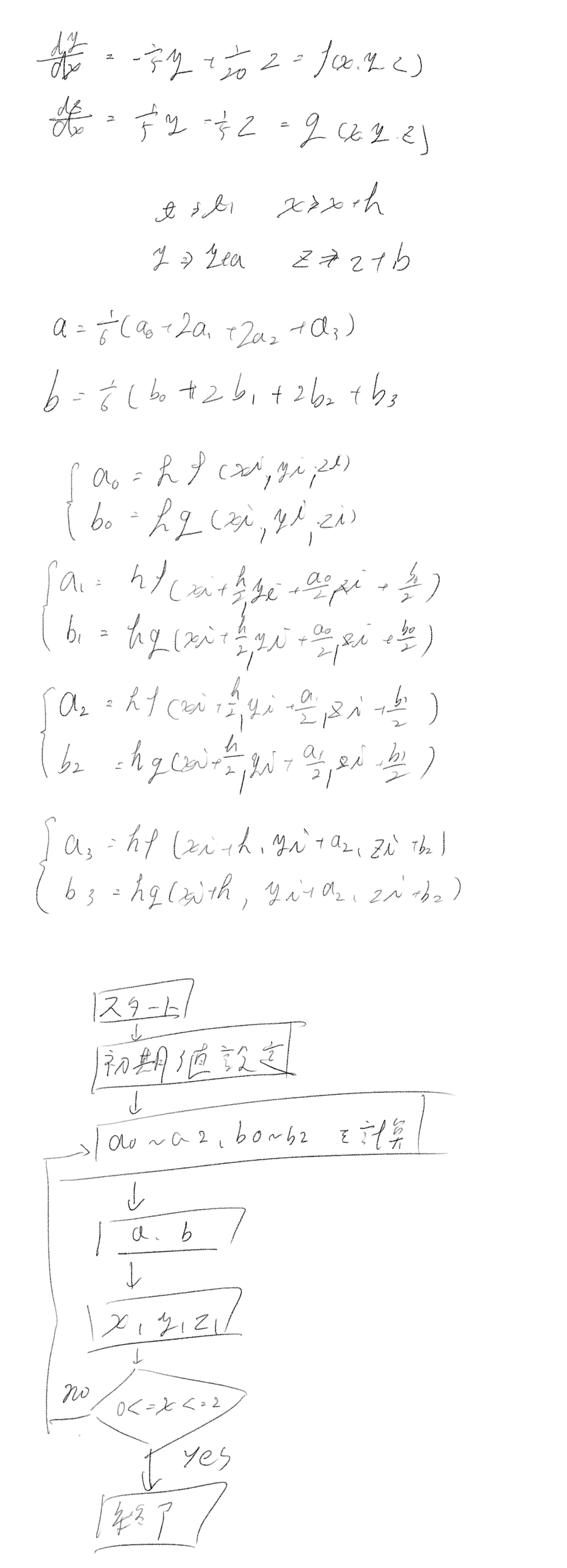
103 投稿者:名無しさん 2020/01/22 13:07:49
#include<stdio.h>
#include<math.h>
#define N 40
float f1(float x,float y,float z)
{
return((-y/5.0)+(z/20.0));
}
float f2(float x,float y,float z)
{
return((y/5.0)-(z/5.0));
}
int main(void)
{
int i;
float x[N+1],y[N+1],z[N+1],X,a,b,a0,b0,a1,b1,a2,b2,a3,b3,h=0.2;
x[0]=0.0;
y[0]=60.0;
z[0]=0.0;
printf(" x , y , z \n");
for(i=0;i<11;i++){
a0=h*f1(x[i],y[i],z[i]);
b0=h*f2(x[i],y[i],z[i]);
a1=h*f1(x[i]+h/2.0,y[i]+a0/2.0,z[i]+b0/2.0);
b1=h*f2(x[i]+h/2.0,y[i]+a0/2.0,z[i]+b0/2.0);
a2=h*f1(x[i]+h/2.0,y[i]+a1/2.0,z[i]+b1/2.0);
b2=h*f2(x[i]+h/2.0,y[i]+a1/2.0,z[i]+b1/2.0);
a3=h*f1(x[i]+h,y[i]+a2,z[i]+b2);
b3=h*f2(x[i]+h,y[i]+a2,z[i]+b2);
a=(a0+2.0*a1+2.0*a2+a3)/6.0;
b=(b0+2.0*b1+2.0*b2+b3)/6.0;
x[i+1]=x[i]+h;
y[i+1]=y[i]+a;
z[i+1]=z[i]+b;
printf("%8.5f %8.5f %8.5f\n",x[i],y[i],z[i]);
}
}
/*実行結果
x , y , z
0.00000 60.00000 0.00000
0.20000 57.65890 2.30605
0.40000 55.43130 4.43214
0.60000 53.31104 6.38966
0.80000 51.29233 8.18931
1.00000 49.36967 9.84115
1.20000 47.53790 11.35464
1.40000 45.79215 12.73868
1.60000 44.12782 14.00162
1.80000 42.54055 15.15131
2.00000 41.02627 16.19514
*/
104 投稿者:名無しさん 2020/01/29 09:23:37
from sklearn import model selection, svm, metrics! import matplotlib.pyplot as pltl import pandas as pd plt.style.use('ggplot')4 717- zICSV) EA t 1(1*) delimiter=";") pd.read csv("winequality-red.csv" !! ["fixed acidity","volatile acidity","citric acid", = sa "chlorides "free sulfur dioxide" y = "residual sugar "total sulfur dioxide", "density", "pH", "sulphates "alcohol"] wine["quality"] # labell fis, axn = plt.subplots(11, sharey-True). for i, name enumerate(names):1 axn[i].set title(name) axn[i].scatter (wine[name], y)4 plt.show(04
105 投稿者:名無しさん 2020/01/29 09:32:36
from sklearn import model selection, svm, metrics! import matplotlib.pyplot as pltl import pandas as pd plt.style.use('ggplot')4 717- zICSV) EA t 1(1*) delimiter=";") pd.read csv("winequality-red.csv" !! ["fixed acidity","volatile acidity","citric acid", = sa "chlorides "free sulfur dioxide" y = "residual sugar "total sulfur dioxide", "density", "pH", "sulphates "alcohol"] wine["quality"] # labell fis, axn = plt.subplots(11, sharey-True). for i, name enumerate(names):1 axn[i].set title(name) axn[i].scatter (wine[name], y)4 plt.show(04